
AI一体机系统主动监测服务
上海眙宝智算科技股份有限公司基於多年伺服器维保经验,开发了先进的AI一体机系统主动监测平台,为客户提供全方位的AI伺服器全生命周期健康管理服务。
1 AI一体机系统软体架构
我司自主研发的AI一体机智能监控系统采用多层架构设计,集成了先进的AI技术,能够实现对GPU伺服器的全天候主动监测、预警和智慧诊断。
系统架构主要包括:
1.1 维修管理平台:整合设备管理、故障跟踪、维修流程管理等功能的顶层应用平台
1.2 API层:
- 专业测试API:提供标准化测试介面
- 知识库检索API:智慧检索故障解决方案
- 报告生成API:自动生成维修和测试报告
- 对话交互API:支援技术人员与系统交互
1.3 专业测试设备层:
- 自动测试系统:执行标准化测试流程
- 视觉检测系统:识别硬体外观异常
- 资料获取系统:收集伺服器运行资料
- AR辅助系统:辅助现场技术操作
1.4 CteEdge-N边缘运算推理系统**:
- Worker架构设计
- 实现当地语系化AI推理能力
1.5 资料型AI SaaS平台:
- 专注於资料处理和模型训练
- 为故障预测和预防性维护提供支援
2 AI监控管理平台模型训练资料流程
我司的AI主动监测系统具有完整的资料流程闭环,通过以下方式实现智慧化资料获取,仪表视觉化监测和潜在系统风险预警:
2.1 资料收集:
- 从客户现场设备收集运行资料
- 通过专业测试设备获取测试资料
- 历史故障维修记录整合
2.2 资料处理与分析:
- 测试资料通过 API层传送至AI训练平台
- 利用AI模型进行资料分析和异常检测
- 模型训练成果部署到CteEdge-N边缘推理系统
2.3预测性维护:
- 即时监测设备运行状态
- 预测潜在故障风险
- 自动生成预防性维护建议
3 AI预训练平台功能
我司AI一体机系统软体架构的核心优势在於其预训练平台:
3.1 基於API的核心层:
- 包含专业测试、知识库检索、报告生成和对等APIAPI
- 提供与协力厂商系统集成的标准介面
3.2 AI模型预训练平台:
- 资料型AI SaaS平台
- 专注於资料处理、模型训练和部署
- 提供回归、分类、时间序列、异常检测等分析工具
- 具备30种以上AI训练模型整合训练
3.3 系统整合优势:
- 互补性整合:AI模型提供资料处理和异常检测底层支援,系统专注於测试执行和视觉检测
- API层整合:提供SDK API,可整合到客户的AI一体机系统中
- 资料流程整合:实现资料获取、分析和报告生成的完整闭环
4 主动监测服务内容
作为维保服务的一部分,我司提供的AI主动监测服务包括:
4.1 即时性能监测:
- GPU利用率和性能指标监控
- 温度和功耗即时监测
- 网路连接状态监控
- 存储性能监测
4.2 异常行为检测:
- 基於AI模型的异常模式识别
- 与历史资料对比分析
- 针对特定GPU型号的优化检测规则
4.3 预警机制:
- 多级预警系统(一般、重要、严重)
- 自订预警阈值设置
- 多管道通知(短信、邮件、系统通知)
- 预警事件追踪管理
4.4故障预测:
- 基於历史资料和故障模式的预测分析
- 部件寿命预测
- 性能退化趋势分析
- 预防性维护建议生成
4.5 智能报告生成:
- 定期健康状况报告
- 故障分析报告
- 性能优化建议报告
- 设备使用效率分析报告
5 部署方案
根据客户需求,我司提供两种主要部署模式:
5.1 本地部署方案:
- CteEdge-N系统部署在客户本地环境
- 支援客户伺服器、PostgreSQL/MySQL/MSSQL资料库
- 提供完全当地语系化的资料处理能力
- 适合资料安全要求高的客户
系统架构图
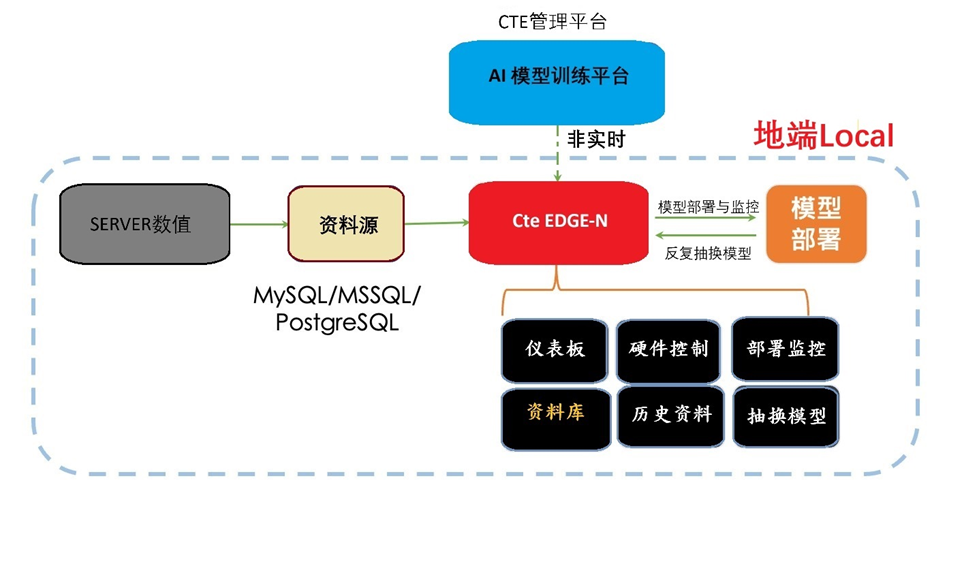
5.2 混合云部署方案:
- 客户服务器与CTE云服务相结合
- 数据库、AI训练平台和CteEdge-N组件云端协同
- 提供更高的扩展性和灵活性
- 适合需要远程管理的分布式服务器集群
系统架构图
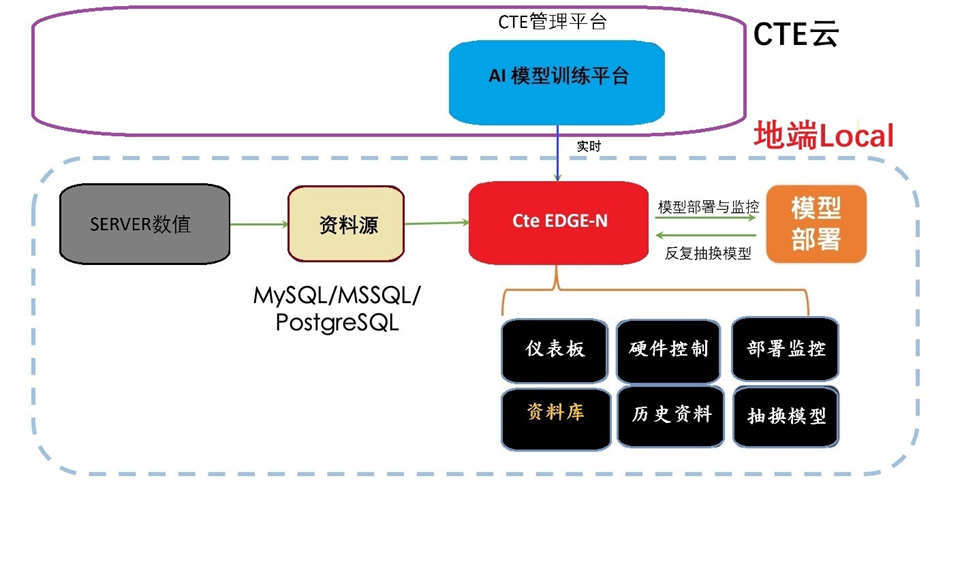
AI伺服器维修与维保
上海眙宝智算科技股份有限公司在松江高科技园区国成立高端AI算力设备服务提供团队,专注於GPU伺服器检测、硬体晶片维修与售后维保服务。我们拥有丰富的GPU维修经验和专业技术团队,是英伟达(NVIDIA)服务合作伙伴,能够为客户提供全方位AI算力设备解决方案。
AI一体机系统主动监测服务
眙宝(上海)光电有限公司基於多年伺服器维保经验,开发了先进的AI一体机系统主动监测平台,为客户提供全方位的AI伺服器全生命周期健康管理服务。
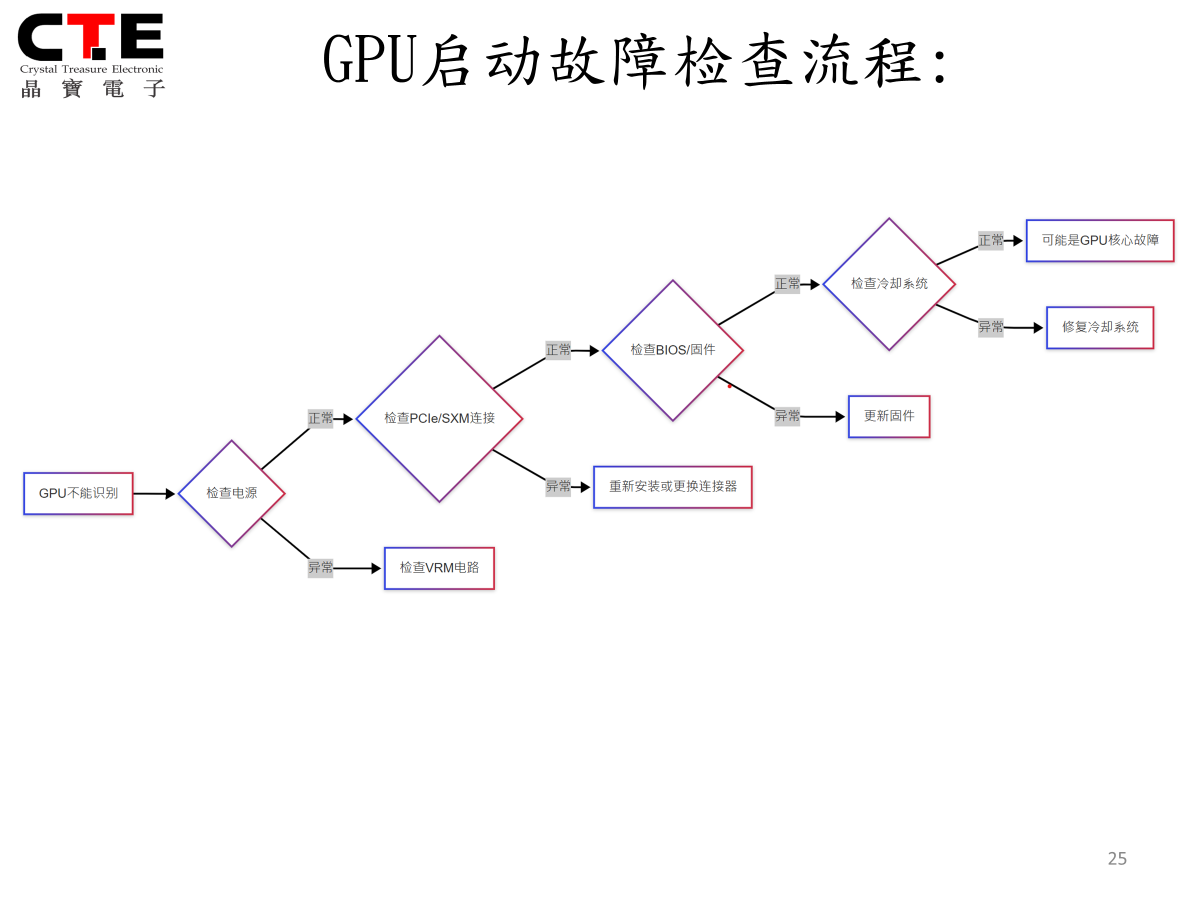
GPU启动故障检查流程步骤:
5.1.1 GPU不能识 → 检查电源
- 正常 → 检查PCIe/SXM连接
- 正常 → 检查BIOS/固件
- 正常 → 检查散热系统
- 正常 → 可能是GPU核心故障
- 异常 → 修复冷却系统
- 异常 → 更新固件
- 异常 → 重新安装或更换接器
- 异常 → 检查VRM电路
此流程确保以系统化方式高效检测故障源,最大限度减少诊断时间。
5.2 GPU启动故障排查详细步骤
为确保高效准确地诊断GPU故障,我们将故障排查过程分为四个主要阶段,每个阶段都有详细的检测项目、方法和解决方案:
|
故障阶段 |
检查项目 |
检查方法 |
可能的解决方案 |
|
电源检查 |
主电源电压 |
测量TP21测试点12V电压 |
修复电源线路或更换电源 |
|
|
VRM输出电压 |
测量GPU核心电压测试点 |
修复或更换损坏的VRM模块 |
|
|
供电稳定性 |
观察电源纹波 |
更换滤波电容或稳压器 |
|
接口检查 |
SXM5连接器 |
目视检查是否有弯曲针脚 |
修复针脚或更换连接器 |
|
|
PCIe接口 |
检查连接器清洁度和插入状态 |
清洁接口或重新安装 |
|
|
辅助电源接口 |
检查连接器接触状态 |
重新插接或更换连接线 |
|
固件检查 |
BIOS设置 |
检查系统BIOS中GPU设置 |
更新BIOS或修改设置 |
|
|
GPU固件 |
检查固件版本和状态 |
更新固件或回滚到稳定版本 |
|
|
设备驱动程序 |
检查驱动程序兼容性 |
更新或重新安装驱动程序 |
|
冷却检查 |
过热保护 |
检查温度传感器读数 |
修复温度检测电路 |
|
|
散热器接触 |
检查散热器安装状态 |
重新安装散热器或更换散热膏 |
|
|
风扇运行 |
检查风扇电路和转速 |
修复风扇电路或更换风扇 |
5.3 GPU关键电气测试点规范
为确保准确诊断GPU电气问题,我们建立了标准化测试点规范:
核心电压测试点:
|
测试点标记 |
预期电压 |
允许偏差 |
位置描述 |
|
TP1 |
0.85V |
±0.02V |
GPU核心左上角 |
|
TP2 |
1.2V |
±0.05V |
内存控制器旁 |
|
TP3 |
0.75V |
±0.02V |
计算单元附近 |
VRM测试点:
|
测试点标记 |
预期电压 |
允许偏差 |
位置描述 |
|
TP21 |
12V |
±0.5V |
主电源输入 |
|
TP22 |
3.3V |
±0.1V |
逻辑电路供电 |
|
TP23 |
5V |
±0.25V |
接口供电 |
信号测试点:
|
测试点标记 |
信号类型 |
预期值 |
位置描述 |
|
TPx1 |
时钟 |
100MHz |
时钟缓冲区旁 |
|
TPx2 |
复位 |
3.3V高电平 |
复位电路旁 |
|
TPx3 |
I2C SCL |
方波 |
侧边第三个焊盘 |
5.4 GPU常见问题排解指南
问题:GPU完全无法识别
可能原因与解决方案:
- SXM5接口接触不良 - 重新安装GPU
- 主板BIOS未启用GPU - 更新BIOS设置
- GPU电源故障 - 检查VRM和供电
- GPU芯片损坏 - 更换整个模块
问题:GPU温度异常高
可能原因与解决方案:
- 散热器接触不良 - 重新安装散热器
- 散热膏问题 - 更换散热膏
- 风扇故障 - 检查风扇连接或更换风扇
- 功耗配置错误 - 检查电源管理设置
问题:GPU性能下降
可能原因与解决方案:
- 散热限制 - 检查温度与散热系统
- 功率限制 - 验证电源设置
- PCIe链路降速 - 检查PCIe接口状态
- 固件过时 - 更新GPU固件
5.5 维修标准化SOP流程
眙宝(上海)光电有限公司已建立完善的维修标准化SOP流程,确保每一台设备都经过严格、标准化的维修过程:
5.5.1 维修前准备
- 工具准备:高精度螺丝刀套装、焊接工具、检测工具、防静电工具、清洁工具
- 备件准备:根据故障类型准备兼容的高质量备件
- 工作环境准备:温度20℃-25℃,湿度40%-60%的专业维修室
5.5.2维修分级与分流
- 根据故障复杂度划分为初级、中级、高级维修
- 按照故障类型分配给相应专业团队
- 建立维修任务跟踪系统
5.5.3 标准维修流程
- 故障确认与记录
- 拆解步骤标准化
- 组件测试与更换
- 电路板焊接标准
- BGA芯片更换工艺规范
- BIOS刷新与配置
- 组装与初步通电测试
5.5.4 质量控制点
- 关键步骤设置质检点
- 双人交叉验证机制
- 多级别测试确认
- 失效分析与改进流程
5.5.5 维修记录管理
- 使用标准化维修记录表格记录维修全过程
- 包含日期、设备序列号、故障描述、维修措施、更换部件、维修人员和验证结果等信息
- 建立维修历史数据库,用于后续分析和改进
5.6 故障卡修复后的压测程序
为确保维修后的GPU设备恢复正常性能并保持长期稳定,我们实施严格的压力测试程序:
5.6.1 基础功能测试
- 设备识别测试
- 基本功能测试
- 接口测试
- 驱动兼容性测试
5.6.2 性能测试
- 标准性能基准测试(使用3DMark等工具)
- CUDA核心功能测试
- 显存带宽测试
- PCIe传输速率测试
5.6.3 稳定性测试
- GPU_BURN持续压力测试(标准时长3600秒)
- 高负载循环测试(8小时)
- 温度应力测试
- 电压波动条件下稳定性测试
5.6.4特殊功能测试
- 多卡协同工作测试
- NVLink通信测试
- 特定应用场景模拟测试
- 异常处理能力测试
5.6.5 数据分析与报告
- 自动化测试数据收集
- 性能对比分析(与标准规格对比)
- 稳定性评分
- 详细测试报告生成
所有修复后的设备必须通过完整的压力测试流程,确保其性能参数达到或接近原厂标准,并能在高负载条件下保持稳定运行。

